3. 简单函数¶
3.1. 数学函数¶
在数学中我们用过 \(\operatorname{sin}\) 和 \(\operatorname{ln}\) 这样的函数,例如 \(\operatorname{sin} ( \pi / 2 ) = 1\) ,\(\operatorname{ln} 1 = 0\) 等等,在C语言中也可以使用这些函数( \(\operatorname{ln}\) 函数在C标准库中叫做 log ):
#include <math.h>
#include <stdio.h>
int main(void)
{
double pi = 3.1416;
printf("sin(pi/2)=%f\nln1=%f\n", sin(pi/2), log(1.0));
return 0;
}
编译运行这个程序,结果如下:
$ gcc main.c -lm
$ ./a.out
sin(pi/2)=1.000000
ln1=0.000000
在数学中写一个函数有时候可以省略括号,而C语言要求一定要加上括号,例如 log(1.0)。在C语言的术语中,1.0 是参数(Argument),log 是函数(Function) ,log(1.0) 是函数调用(Function Call) 。sin(pi/2) 和 log(1.0) 这两个函数调用在我们的 printf 语句中处于什么位置呢?在上一章讲过,这应该是写表达式的位置。因此函数调用也是一种表达式,这个表达式由函数调用运算符( () 括号)和两个操作数组成,操作数 log 是一个函数名(Function Designator) ,它的类型是一种函数类型(Function Type) ,操作数 1.0 是 double 型的。log(1.0) 这个表达式的值就是对数运算的结果,也是 double 型的,在C语言中函数调用表达式的值称为函数的返回值(Return Value) 。总结一下我们新学的语法规则:
表达式 → 函数名
表达式 → 表达式(参数列表)
参数列表 → 表达式, 表达式, …
现在我们可以完全理解 printf 语句了:原来 printf 也是一个函数,上例中的 printf("sin(pi/2)=%f\nln1=%f\n", sin(pi/2), log(1.0)) 是带三个参数的函数调用,而函数调用也是一种表达式,因此 printf 语句也是表达式语句的一种。但是 printf 感觉不像一个数学函数,为什么呢?因为像 log 这种函数,我们传进去一个参数会得到一个返回值,我们调用 log 函数就是为了得到它的返回值,至于 printf,我们并不关心它的返回值(事实上它也有返回值,表示实际打印的字符数),我们调用 printf 不是为了得到它的返回值,而是为了利用它所产生的副作用(Side Effect) --打印。C语言的函数可以有Side Effect,这一点是它和数学函数在概念上的根本区别。
Side Effect这个概念也适用于运算符组成的表达式。比如 a + b 这个表达式也可以看成一个函数调用,把运算符 + 看作函数,它的两个参数是 a 和 b,返回值是两个参数的和,传入两个参数,得到一个返回值,并没有产生任何Side Effect。而赋值运算符是有Side Effect的,如果把 a = b 这个表达式看成函数调用,返回值就是所赋的值,既是 b 的值也是 a 的值,但除此之外还产生了Side Effect,就是变量a被改变了,改变计算机存储单元里的数据或者做输入输出操作都算Side Effect。
回想一下我们的学习过程,一开始我们说赋值是一种语句,后来学了表达式,我们说赋值语句是表达式语句的一种;一开始我们说 printf 是一种语句,现在学了函数,我们又说 printf 也是表达式语句的一种。随着我们一步步的学习,把原来看似不同类型的语句统一成一种语句了。学习的过程总是这样,初学者一开始接触的很多概念从严格意义上说是错的,但是很容易理解,随着一步步学习,在理解原有概念的基础上不断纠正,不断泛化(Generalize) 。比如一年级老师说小数不能减大数,其实这个概念是错的,后来引入了负数就可以减了,后来引入了分数,原来的正数和负数的概念就泛化为整数,上初中学了无理数,原来的整数和分数的概念就泛化为有理数,再上高中学了复数,有理数和无理数的概念就泛化为实数。坦白说,到目前为止本书的很多说法都是不完全正确的,但这是学习理解的必经阶段,到后面的章节都会逐步纠正的。
程序第一行的 # 号(Pound Sign,Number Sign或Hash Sign) 和 include 表示包含一个头文件(Header File) ,后面尖括号(Angel Bracket) 中就是文件名(这些头文件通常位于 /usr/include 目录下)。头文件中声明了我们程序中使用的库函数,根据先声明后使用的原则,要使用 printf 函数必须包含 stdio.h,要使用数学函数必须包含 math.h,如果什么库函数都不使用就不必包含任何头文件,例如写一个程序 int main(void){int a;a=2;return 0;},不需要包含头文件就可以编译通过,当然这个程序什么也做不了。
使用 math.h 中声明的库函数还有一点特殊之处,gcc命令行必须加 -lm 选项,因为数学函数位于 libm.so 库文件中(这些库文件通常位于 /lib 目录下),-lm 选项告诉编译器,我们程序中用到的数学函数要到这个库文件里找。本书用到的大部分库函数(例如 printf)位于 libc.so 库文件中,使用 libc.so 中的库函数在编译时不需要加 -lc 选项,当然加了也不算错,因为这个选项是gcc的 默认选项。关于头文件和库函数目前理解这么多就可以了,到 链接详解 再详细解释。
重要
C标准库和glibc
C标准主要由两部分组成,一部分描述C的语法,另一部分描述C标准库。C标准库定义了一组标准头文件,每个头文件中包含一些相关的函数、变量、类型声明和宏定义。要在一个平台上支持C语言,不仅要实现C编译器,还要实现C标准库,这样的实现才算符合C标准。不符合C标准的实现也是存在的,例如很多单片机的C语言开发工具中只有C编译器而没有完整的C标准库。
在Linux平台上最广泛使用的C函数库是 glibc,其中包括C标准库的实现,也包括本书第三部分介绍的所有系统函数。几乎所有C程序都要调用glibc的库函数,所以glibc是Linux平台C程序运行的基础。glibc提供一组头文件和一组库文件,最基本、最常用的C标准库函数和系统函数在 libc.so 库文件中,几乎所有C程序的运行都依赖于 libc.so,有些做数学计算的C程序依赖于 libm.so,以后我们还会看到多线程的C程序依赖于 libpthread.so。以后我说libc时专指 libc.so 这个库文件,而说 glibc 时指的是 glibc 提供的所有库文件。
glibc并不是Linux平台唯一的基础C函数库,也有人在开发别的C函数库,比如适用于嵌入式系统的uClibc。
3.2. 自定义函数¶
我们不仅可以调用C标准库提供的函数,也可以定义自己的函数,事实上我们已经这么做了:我们定义了 main 函数。例如:
int main(void)
{
int hour = 11;
int minute = 59;
printf("%d and %d hours\n", hour, minute / 60);
return 0;
}
main 函数的特殊之处在于执行程序时它自动被操作系统调用,操作系统就认准了 main 这个名字,除了名字特殊之外,main 函数和别的函数没有区别。我们对照着 main 函数的定义来看语法规则:
函数定义 → 返回值类型 函数名(参数列表) 函数体
函数体 → { 语句列表 }
语句列表 → 语句列表项 语句列表项 …
语句列表项 → 语句
语句列表项 → 变量声明、类型声明或非定义的函数声明
非定义的函数声明 → 返回值类型 函数名(参数列表);
我们稍后再详细解释“函数定义”和“非定义的函数声明”的区别。从 结构体 开始我们才会看到类型声明,所以现在暂不讨论。
给函数命名也要遵循上一章讲过的标识符命名规则。由于我们定义的 main 函数不带任何参数,参数列表应写成 void 。函数体可以由若干条语句和声明组成,C89要求所有声明写在所有语句之前(本书的示例代码都遵循这一规定),而C99的新特性允许语句和声明按任意顺序排列,只要每个标识符都遵循先声明后使用的原则就行。 main 函数的返回值是 int 型的,return 0; 这个语句表示返回值是 0,main 函数的返回值是返回给操作系统看的,因为 main 函数是被操作系统调用的,通常程序执行成功就返回 0,在执行过程中出错就返回一个非零值。比如我们将 main 函数中的 return 语句改为 return 4; 再执行它,执行结束后可以在Shell中看到它的退出状态(Exit Status) :
$ ./a.out
11 and 0 hours
$ echo $?
4
$? 是Shell中的一个特殊变量,表示上一条命令的退出状态。关于 main 函数需要注意两点:
- [K&R] 书上的
main函数定义写成main(){...}的形式,不写返回值类型也不写参数列表,这是Old Style C的风格。Old Style C规定不写返回值类型就表示返回int型,不写参数列表就表示参数类型和个数没有明确指出。这种宽松的规定使编译器无法检查程序中可能存在的Bug,增加了调试难度,不幸的是现在的C标准为了兼容旧的代码仍然保留了这种语法,但读者绝不应该继续使用这种语法。 - 其实操作系统在调用
main函数时是传参数的,main函数最标准的形式应该是int main(int argc, char *argv[]),在 指向指针的指针与指针数组 详细介绍。C标准也允许int main(void)这种写法,如果不使用系统传进来的两个参数也可以写成这种形式。但除了这两种形式之外,定义main函数的其它写法都是错误的或不可移植的。
关于返回值和 return 语句我们将在 return语句 详细讨论,我们先从不带参数也没有返回值的函数开始学习定义和使用函数:
#include <stdio.h>
void newline(void)
{
printf("\n");
}
int main(void)
{
printf("First Line.\n");
newline();
printf("Second Line.\n");
return 0;
}
执行结果:
First Line.
Second Line.
我们定义了一个 newline 函数给 main 函数调用,它的作用是打印一个换行,所以执行结果中间多了一个空行。 newline 函数不仅不带参数,也没有返回值,返回值类型为 void 表示没有返回值 [1],这说明我们调用这个函数完全是为了利用它的Side Effect。如果我们想要多次插入空行就可以多次调用 newline 函数:
int main(void)
{
printf("First Line.\n");
newline();
newline();
newline();
printf("Second Line.\n");
return 0;
}
如果我们总需要三个三个地插入空行,我们可以再定义一个 threeline 函数每次插入三个空行:
#include <stdio.h>
void newline(void)
{
printf("\n");
}
void threeline(void)
{
newline();
newline();
newline();
}
int main(void)
{
printf("Three lines:\n");
threeline();
printf("Another three lines.\n");
threeline();
return 0;
}
通过这个简单的例子可以体会到:
- 同一个函数可以被多次调用。
- 可以用一个函数调用另一个函数,后者再去调第三个函数。
- 通过自定义函数可以给一组复杂的操作起一个简单的名字,例如
threeline。对于``main`` 函数来说,只需要通过threeline这个简单的名字来调用就行了,不必知道打印三个空行具体怎么做,所有的复杂操作都被隐藏在threeline这个名字后面。 - 使用自定义函数可以使代码更简洁,
main函数在任何地方想打印三个空行只需调用一个简单的threeline(),而不必每次都写三个printf("\n")。
读代码和读文章不一样,按从上到下从左到右的顺序读代码未必是最好的。比如上面的例子,按源文件的顺序应该是先看 newline 再看 threeline 再看 main 。如果你换一个角度,按 代码的执行顺序 来读也许会更好:首先执行的是 main 函数中的语句,在一条 printf 之后调用了 threeline,这时再去看 threeline 的定义,其中又调用了 newline ,这时再去看 newline 的定义,newline 里面有一条 printf,执行完成后返回 threeline,这里还剩下两次 newline 调用,效果也都一样,执行完之后返回 main,接下来又是一条 printf 和一条 threeline。如下图所示:
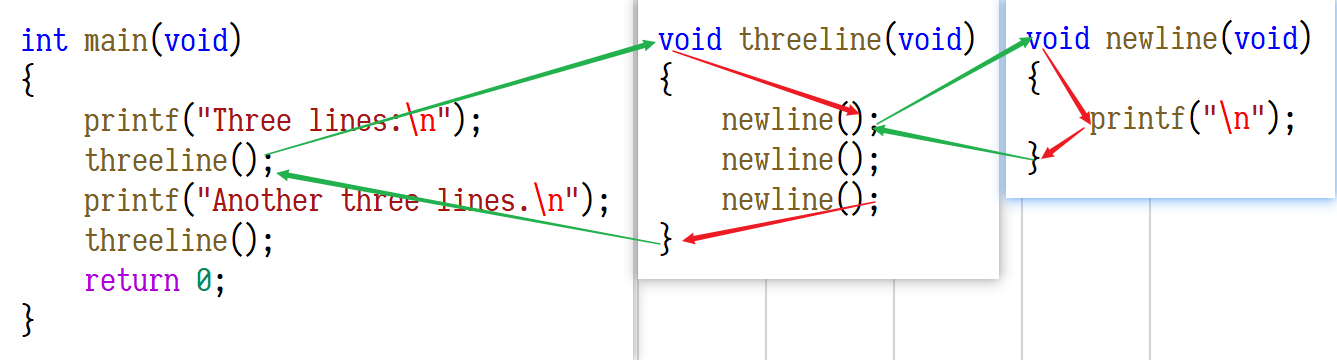
读代码的过程就是模仿计算机执行程序的过程,我们不仅要记住当前读到了哪一行代码,还要记住现在读的代码是被哪个函数调用的,这段代码返回后应该从上一个函数的什么地方接着往下读。
现在澄清一下函数声明、函数定义、函数原型(Prototype) 这几个概念。比如 void threeline(void) 这一行,声明了一个函数的名字、参数类型和个数、返回值类型,这称为函数原型。在代码中可以单独写一个函数原型,后面加 ; 号结束,而不写函数体,例如:
void threeline(void);
这种写法只能叫函数声明而不能叫函数定义,只有带函数体的声明才叫定义。上一章讲过,只有分配存储空间的变量声明才叫变量定义,其实函数也是一样,编译器只有见到函数定义才会生成指令,而指令在程序运行时当然也要占存储空间。那么没有函数体的函数声明有什么用呢?它为编译器提供了有用的信息,编译器在翻译代码的过程中,只有见到函数原型(不管带不带函数体)之后才知道这个函数的名字、参数类型和返回值,这样碰到函数调用时才知道怎么生成相应的指令,所以函数原型必须出现在函数调用之前,这也是遵循“先声明后使用”的原则。
注解
Zombie110year
在进行多文件编译时, 为了让一个文件编译得到的代码能够使用另一个文件中的变量、函数,需要使用 “声明” 而不是 “定义”。
在上面的例子中,main 调用 threeline,threeline 再调用 newline ,要保证每个函数的原型出现在调用之前,就只能按先 newline 再 threeline 再 main 的顺序定义了。如果使用不带函数体的声明,则可以改变函数的定义顺序:
#include <stdio.h>
void newline(void);
void threeline(void);
int main(void)
{
...
}
void newline(void)
{
...
}
void threeline(void)
{
...
}
这样仍然遵循了先声明后使用的原则。
由于有Old Style C语法的存在,并非所有函数声明都包含完整的函数原型,例如 void threeline(); 这个声明并没有明确指出参数类型和个数,所以不算函数原型,这个声明提供给编译器的信息只有函数名和返回值类型。如果在这样的声明之后调用函数,编译器不知道参数的类型和个数,就不会做语法检查,所以很容易引入Bug。读者需要了解这个知识点以便维护别人用Old Style C风格写的代码,但绝不应该按这种风格写新的代码。
如果在调用函数之前没有声明会怎么样呢?有的读者也许碰到过这种情况,我可以解释一下,但绝不推荐这种写法。比如按上面的顺序定义这三个函数,但是把开头的两行声明去掉:
#include <stdio.h>
int main(void)
{
printf("Three lines:\n");
threeline();
printf("Another three lines.\n");
threeline();
return 0;
}
void newline(void)
{
printf("\n");
}
void threeline(void)
{
newline();
newline();
newline();
}
编译时会报警告:
$ gcc main.c
main.c:17: warning: conflicting types for ‘threeline’
main.c:6: warning: previous implicit declaration of ‘threeline’ was here
但仍然能编译通过,运行结果也对。这里涉及到的规则称为函数的隐式声明(Implicit Declaration) ,在 main 函数中调用 threeline 时并没有声明它,编译器认为此处隐式声明了 int threeline(void);,隐式声明的函数返回值类型都是 int,由于我们调用这个函数时没有传任何参数,所以编译器认为这个隐式声明的参数类型是 void,这样函数的参数和返回值类型都确定下来了,编译器根据这些信息为函数调用生成相应的指令。然后编译器接着往下看,看到 threeline 函数的原型是 void threeline(void),和先前的隐式声明的返回值类型不符,所以报警告。好在我们也没用到这个函数的返回值,所以执行结果仍然正确。
| [1] | 敏锐的读者可能会发现一个矛盾:如果函数 newline 没有返回值,那么表达式 newline() 不就没有值了吗?然而上一章讲过任何表达式都有值和类型两个基本属性。其实这正是设计 void 这么一个关键字的原因:首先从语法上规定没有返回值的函数调用表达式有一个 void 类型的值,这样任何表达式都有值,不必考虑特殊情况,编译器的语法解析比较容易实现;然后从语义上规定 void 类型的表达式不能参与运算,因此 newline() + 1 这样的表达式不能通过语义检查,从而兼顾了语法上的一致和语义上的不矛盾。 |
3.3. 形参和实参¶
下面我们定义一个带参数的函数,我们需要在函数定义中指明参数的个数和每个参数的类型,定义参数就像定义变量一样,需要为每个参数指明类型,参数的命名也要遵循标识符命名规则。例如:
#include <stdio.h>
void print_time(int hour, int minute)
{
printf("%d:%d\n", hour, minute);
}
int main(void)
{
print_time(23, 59);
return 0;
}
需要注意的是,定义变量时可以把相同类型的变量列在一起,而定义参数却不可以,例如下面这样的定义是错的:
void print_time(int hour, minute)
{
printf("%d:%d\n", hour, minute);
}
学习C语言的人肯定都乐意看到这句话:“变量是这样定义的,参数也是这样定义的,一模一样”,这意味着不用专门去记住参数应该怎么定义了。谁也不愿意看到这句话:“定义变量可以这样写,而定义参数却不可以”。C语言的设计者也不希望自己设计的语法规则里到处都是例外,一个容易被用户接受的设计应该遵循最少例外原则(Rule of Least Surprise) 。其实关于参数的这条规定也不算十分例外,也是可以理解的,请读者想想为什么要这么规定。学习编程语言不应该死记各种语法规定,如果能够想清楚设计者这么规定的原因(Rationale) ,不仅有助于记忆,而且会有更多收获。本书在必要的地方会解释一些Rationale,或者启发读者自己去思考,例如上一节在脚注中解释了 void 关键字的Rationale。 [C99 Rationale] 是随C99标准一起发布的,值得参考。
总的来说,C语言的设计是非常优美的,只要理解了少数基本概念和基本原则就可以根据组合规则写出任意复杂的程序,很少有例外的规定说这样组合是不允许的,或者那样类推是错误的。相反,C++的设计就非常复杂,充满了例外,全世界没几个人能把C++的所有规则都牢记于心,因而C++的设计一直饱受争议,这个观点在 [UNIX编程艺术] 中有详细阐述。
在本书中,凡是提醒读者注意的地方都是多少有些Surprise的地方,初学者如果按常理来想很可能要想错,所以需要特别提醒一下。而初学者容易犯的另外一些错误,完全是因为没有掌握好基本概念和基本原理,或者根本无视组合规则而全凭自己主观臆断所致,对这一类问题本书不会做特别的提醒,例如有的初学者看完 常量、变量和表达式 之后会这样打印 \(\pi\) 的值:
double pi=3.1416;
printf("pi\n");
之所以会犯这种错误,一是不理解Literal的含义,二是自己想当然地把变量名组合到字符串里去,而事实上根本没有这条语法规则。如果连这样的错误都需要在书上专门提醒,就好比提醒小孩吃饭一定要吃到嘴里,不要吃到鼻子里,更不要吃到耳朵里一样。
回到正题。我们调用 print_time(23, 59) 时,函数中的参数 hour 就代表 23,参数 minute 就代表59。确切地说,当我们讨论函数中的 hour 这个参数时,我们所说的“ 参数”是指形参(Parameter) ,当我们讨论传一个参数 23 给函数时,我们所说的“参数”是指实参(Argument) ,但我习惯都叫参数而不习惯总把形参、实参这两个文绉绉的词挂在嘴边(事实上大多数人都不习惯),读者可以根据上下文判断我说的到底是形参还是实参。记住这条基本原理:形参相当于函数中定义的变量,调用函数传递参数的过程相当于定义形参变量并且用实参的值来初始化。例如这样调用:
void print_time(int hour, int minute)
{
printf("%d:%d\n", hour, minute);
}
int main(void)
{
int h = 23, m = 59;
print_time(h, m);
return 0;
}
相当于在函数print_time中执行了这样一些语句:
int hour = h;
int minute = m;
printf("%d:%d\n", hour, minute);
main 函数的变量 h 和 print_time 函数的参数 hour 是两个不同的变量,只不过它们的存储空间中都保存了相同的值 23,因为变量 h 的值赋给了参数 hour。同理,变量 m 的值赋给了参数 minute。C语言的这种传递参数的方式称为Call by Value 。在调用函数时,每个参数都需要得到一个值,函数定义中有几个形参,在调用时就要传几个实参,不能多也不能少,每个参数的类型也必须对应上。
肯定有读者注意到了,为什么我们每次调用 printf 传的实参个数都不一样呢?因为C语言规定了一种特殊的参数列表格式,用命令 man 3 printf 可以查看到 printf 函数的原型:
int printf(const char *format, ...);
第一个参数是 const char * 类型的,后面的 ... 可以代表 0 个或任意多个参数,这些参数的类型也是不确定的,这称为可变参数(Variable Argument) , 可变参数 将会详细讨论这种格式。总之,每个函数的原型都明确规定了返回值类型以及参数的类型和个数,即使像 printf 这样规定为“不确定”也是一种明确的规定,调用函数时要严格遵守这些规定,有时候我们把函数叫做接口(Interface) ,调用函数就是使用这个接口,使用接口的前提是必须和接口保持一致。
重要
Man Page
Man Page是Linux开发最常用的参考手册,由很多页面组成,每个页面描述一个主题,这些页面被组织成若干个Section。FHS(Filesystem Hierarchy Standard) 标准规定了Man Page各Section的含义如下:
| Section | 描述 |
| 1 | 用户命令,例如 ls(1) |
| 2 | 系统调用,例如 _exit(2) |
| 3 | 库函数,例如 printf(3) |
| 4 | 特殊文件,例如 null(4) 描述了设备文件
/dev/null、/dev/zero 的作用 |
| 5 | 系统配置文件的格式,例如 passwd(5) 描述了
系统配置文件 /etc/passwd 的格式 |
| 6 | 游戏 |
| 7 | 其它杂项,例如 bash-builtins(7)
描述了 bash 的各种内建命令 |
| 8 | 系统管理命令,例如 ifconfig(8) |
注意区分用户命令和系统管理命令,用户命令通常位于 /bin 和 /usr/bin 目录,系统管理命令通常位于 /sbin 和 /usr/sbin 目录,一般用户可以执行用户命令,而执行系统管理命令经常需要 root 权限。系统调用和库函数的区别将在 main函数和启动例程 说明。
Man Page中有些页面有重名,比如敲 man printf 命令看到的并不是C函数 printf,而是位于第1个Section的系统命令 printf ,要查看位于第3个Section的 printf 函数应该敲 man 3 printf,也可以敲 man -k printf 命令搜索哪些页面的主题包含 printf 关键字。本书会经常出现类似 printf(3) 这样的写法,括号中的 3 表示 Man Page 的第 3 个 Section,或者表示 “我这里想说的是 printf 库函数而不是 printf 命令”。
3.3.1. 习题¶
1、定义一个函数 increment,它的作用是把传进来的参数加 1。例如:
void increment(int x)
{
x = x + 1;
}
int main(void)
{
int i = 1, j = 2;
increment(i); /* i now becomes 2 */
increment(j); /* j now becomes 3 */
return 0;
}
我们在 main 函数中调用 increment 增加变量 i 和 j 的值,这样能奏效吗?为什么?
注解
Zombie110year
并不能. 因为在调用 increment 时, 传入的值会在 increment 的作用域中创建一个新的内存区域. 实际上, 在 increment 中的 i 和在 main 中的 i 并不是同一块内存. 由于 increment 没有返回值, 那么在调用结束后, 内部的变量就被直接销毁了.
2、如果在一个程序中调用了 printf 函数却不包含头文件,例如 int main(void) { printf("\n"); },编译时会报警告: warning: incompatible implicit declaration of built-in function ‘printf’。请分析错误原因。
注解
Zombie110year
由于没有引用 stdio.h, 因此, 编译器找不到 printf 标识符的定义, 就算默认链接了 libc.so, 也不知道该执行哪一段机器码. 编译器在编译过程中, 会对其进行检查, 因此报错.
3.4. 全局变量、局部变量和作用域¶
我们把函数中定义的变量称为局部变量(Local Variable) ,由于形参相当于函数中定义的变量,所以形参也是一种局部变量。在这里“局部”有两层含义:
1、一个函数中定义的变量不能被另一个函数使用。例如 print_time 中的 hour 和 minute 在 main 函数中没有定义,不能使用,同样 main 函数中的局部变量也不能被 print_time 函数使用。如果这样定义:
void print_time(int hour, int minute)
{
printf("%d:%d\n", hour, minute);
}
int main(void)
{
int hour = 23, minute = 59;
print_time(hour, minute);
return 0;
}
main 函数中定义了局部变量 hour , print_time 函数中也有参数 hour ,虽然它们名称相同,但仍然是两个不同的变量,代表不同的存储单元。 main 函数的局部变量 minute 和 print_time 函数的参数 minute 也是如此。
2、每次调用函数时局部变量都表示不同的存储空间。局部变量在每次函数调用时分配存储空间,在每次函数返回时释放存储空间,例如调用 print_time(23, 59) 时分配 hour 和 minute 两个变量的存储空间,在里面分别存上 23 和 59 ,函数返回时释放它们的存储空间,下次再调用 print_time(12, 20) 时又分配 hour 和 minute 的存储空间,在里面分别存上 12 和 20。
与局部变量的概念相对的是全局变量(Global Variable) ,全局变量定义在所有的函数体之外,它们在程序开始运行时分配存储空间,在程序结束时释放存储空间,在任何函数中都可以访问全局变量,例如:
#include <stdio.h>
int hour = 23, minute = 59;
void print_time(void)
{
printf("%d:%d in print_time\n", hour, minute);
}
int main(void)
{
print_time();
printf("%d:%d in main\n", hour, minute);
return 0;
}
正因为全局变量在任何函数中都可以访问,所以在程序运行过程中全局变量被读写的顺序从源代码中是看不出来的,源代码的书写顺序并不能反映函数的调用顺序。程序出现了Bug往往就是因为在某个不起眼的地方对全局变量的读写顺序不正确,如果代码规模很大,这种错误是很难找到的。而对局部变量的访问不仅局限在一个函数内部,而且局限在一次函数调用之中,从函数的源代码很容易看出访问的先后顺序是怎样的,所以比较容易找到Bug。因此,虽然全局变量用起来很方便,但一定要慎用,能用函数传参代替的就不要用全局变量。
如果全局变量和局部变量重名了会怎么样呢?如果上面的例子改为:

则第一次调用 print_time 打印的是全局变量的值,第二次直接调用 printf 打印的则是 main 函数局部变量的值。在C语言中每个标识符都有特定的作用域,全局变量是定义在所有函数体之外的标识符,它的作用域从定义的位置开始直到源文件结束,而 main 函数局部变量的作用域仅限于 main 函数之中。如上图所示,设想整个源文件是一张大纸,也就是全局变量的作用域,而 main 函数是盖在这张大纸上的一张小纸,也就是 main 函数局部变量的作用域。在小纸上用到标识符 hour 和 minute 时应该参考小纸上的定义,因为大纸(全局变量的作用域)被盖住了,如果在小纸上用到某个标识符却没有找到它的定义,那么再去翻看下面的大纸上有没有定义,例如上图中的变量 x。

到目前为止我们在初始化一个变量时都是用常量做Initializer,其实也可以用表达式做Initializer,但要注意一点:局部变量可以用类型相符的任意表达式来初始化,而全局变量只能用常量表达式(Constant Expression)初始化。例如,全局变量 pi 这样初始化是合法的:
double pi = 3.14 + 0.0016;
但这样初始化是不合法的:
double pi = acos(-1.0);
然而局部变量这样初始化却是可以的。程序开始运行时要用适当的值来初始化全局变量,所以初始值必须保存在编译生成的可执行文件中,因此 初始值在编译时就要计算出来 ,然而上面第二种Initializer的值必须在程序运行时调用 acos 函数才能得到,所以不能用来初始化全局变量。请注意区分编译时和运行时这两个概念。为了简化编译器的实现,C语言从语法上规定全局变量只能用常量表达式来初始化,因此下面这种全局变量初始化是不合法的:
int minute = 360; int hour = minute / 60;
虽然在编译时计算出 hour 的初始值是可能的,但是 minute / 60 不是常量表达式,不符合语法规定,所以编译器不必想办法去算这个初始值。
注解
Zombie110year
如果要用一个标识符表示一个常量(可以在编译时得到的量), 使用 const 关键字.
const int minute = 360;
int hour = minute / 60;
就能通过编译了.
如果全局变量在定义时不初始化则初始值是0,如果局部变量在定义时不初始化则初始值是不确定的,为内存中的垃圾值,也就是之前程序运行的残留。所以,局部变量在使用之前一定要先赋值,如果基于一个不确定的值做后续计算肯定会引入Bug。
如何证明“局部变量的存储空间在每次函数调用时分配,在函数返回时释放”?当我们想要确认某些语法规则时,可以查教材,也可以查C99,但最快捷的办法就是编个小程序验证一下:
#include <stdio.h>
void foo(void)
{
int i;
printf("%d\n", i);
i = 777;
}
int main(void)
{
foo();
foo();
return 0;
}
第一次调用 foo 函数,分配变量 i 的存储空间,然后打印 i 的值,由于 i 未初始化,打印的应该是一个不确定的值,然后把 i 赋值为 777 ,函数返回,释放 i 的存储空间。第二次调用 foo 函数,分配变量 i 的存储空间,然后打印 i 的值,由于 i 未初始化,如果打印的又是一个不确定的值,就证明了“局部变量的存储空间在每次函数调用时分配,在函数返回时释放”。分析完了,我们运行程序看看是不是像我们分析的这样:
134518128 777
结果出乎意料,第二次调用打印的 i 值正是第一次调用末尾赋给 i 的值 777。有一种初学者是这样,原本就没有把这条语法规则记牢,或者对自己的记忆力没信心,看到这个结果就会想:哦那肯定是我记错了,改过来记吧,应该是“函数中的局部变量具有一直存在的固定的存储空间,每次函数调用时使用它,返回时也不释放,再次调用函数时它应该还能保持上次的值”。还有一种初学者是怀疑论者或不可知论者,看到这个结果就会想:教材上明明说“ 局部变量的存储空间在每次函数调用时分配,在函数返回时释放”,那一定是教材写错了,教材也是人写的,是人写的就难免出错,哦,连C99也这么写的啊,C99也是人写的,也难免出错,或者C99也许没错,但是反正运行结果就是错了,计算机这东西真靠不住,太容易受电磁干扰和宇宙射线影响了,我的程序写得再正确也有可能被干扰得不能正确运行。
这是初学者最常见的两种心态。不从客观事实和逻辑推理出发分析问题的真正原因,而仅凭主观臆断胡乱给问题定性,“说你有罪你就有罪”。先不要胡乱怀疑,我们再做一次实验,在两次 foo 函数调用之间插一个别的函数调用,结果就大不相同了:
int main(void)
{
foo();
printf("hello\n");
foo();
return 0;
}
结果是:
134518200
hello
0
这一回,第二次调用 foo 打印的 i 值又不是 777 了而是 0,“局部变量的存储空间在每次函数调用时分配,在函数返回时释放”这个结论似乎对了,但另一个结论又不对了:全局变量不初始化才是 0 啊,不是说“局部变量不初始化则初值不确定”吗?
关键的一点是,我说“初值不确定”,有没有说这个不确定值不能是0?有没有说这个不确定值不能是上次调用赋的值?在这里“不确定”的准确含义是:每次调用这个函数时局部变量的初值可能不一样,运行环境不同,函数的调用次序不同,都会影响到局部变量的初值。在运用逻辑推理时一定要注意,不要把必要条件(Necessary Condition)当充分条件(Sufficient Condition),这一点在Debug时尤其重要,看到错误现象不要轻易断定原因是什么,一定要考虑再三,找出它的真正原因。例如,不要看到第二次调用打印 777 就下结论 “函数中的局部变量具有一直存在的固定的存储空间,每次函数调用时使用它,返回时也不释放,再次调用函数时它应该还能保持上次的值”,这个结论倒是能推出 777 这个结果,但反过来由 777 这个结果却不能推出这样的结论。所以说 777 这个结果是该结论的必要条件,但不是充分条件。也不要看到第二次调用打印 0 就断定“局部变量未初始化则初值为 0 ”, 0 这个结果是该结论的必要条件,但也不是充分条件。至于为什么会有这些现象,为什么这个不确定的值刚好是 777 ,或者刚好是 0 ,等学到 研究函数的调用过程 就能解释这些现象了。
从 自定义函数 介绍的语法规则可以看出,非定义的函数声明也可以写在局部作用域中,例如:
int main(void)
{
void print_time(int, int);
print_time(23, 59);
return 0;
}
这样声明的标识符 print_time 具有局部作域,只在 main 函数中是有效的函数名,出了 main 函数就不存在 print_time 这个标识符了。
写非定义的函数声明时参数可以只写类型而不起名,例如上面代码中的 void print_time(int, int); ,只要告诉编译器参数类型是什么,编译器就能为 print_time(23, 59) 函数调用生成正确的指令。另外注意,虽然在一个函数体中可以声明另一个函数,但不能定义另一个函数,C语言不允许嵌套定义函数 [2]。
| [2] | 但gcc的扩展特性允许嵌套定义函数,但这并不是 C 标准。本书不做详细讨论。在以下网站可以找到一些资料:: http://gcc.gnu.org/onlinedocs/gccint/Trampolines.html http://blog.bitfoc.us/p/82 |